 2024/10/15 07:32
2024/10/15 07:32
2024/10/15 07:32
2024/10/15 07:32
标题:Manipulate-Anything: Automating Real-World Robots using Vision-Language Models
作者:Jiafei Duan、Wentao Yuan、Wilbert Pumacay、Yi Ru Wang、Kiana Ehsani、Dieter Fox、Ranjay Krishna
机构:University of Washington、NVIDIA、Allen Institute for Artifical Intelligence、Universidad Católica San Pablo
原文链接:https://robot-ma.github.io/MA_paper.pdf
代码链接:https://robot-ma.github.io/
官方主页:https://robot-ma.github.io/
像RT-1这样的大规模努力和像Open-X-embodiety这样的广泛社区努力已经对机器人演示数据的规模增长做出了贡献。然而,仍然有机会提高机器人演示数据的质量、数量和多样性。尽管视觉语言模型已被证明能自动生成演示数据,但它们的效用仅限于具有特权状态信息的环境,它们需要手工设计的技能,并且仅限于与少数对象实例的交互。我们提出了MANIPULATE-everything,一种用于现实世界机器人操作的可扩展自动生成方法。与以前的工作不同,我们的方法可以在没有任何特权状态信息、手工设计的技能的情况下在真实世界环境中操作,并且可以操纵任何静态对象。我们使用两种设置来评估我们的方法。首先,MANIPULATE-ANYTHING成功地为所有7个真实世界和14个模拟任务生成轨迹,明显优于现有的方法,如VoxPoser。第二,MANIPULATE-everything的演示可以训练比人类演示训练更健壮的行为克隆策略,或者从VoxPoser,Scaling-up-eliting-Down和Code-As-Policies生成的数据中训练。我们相信,任何操作都可以成为一种可扩展的方法,既可以为机器人生成数据,也可以在零样本环境下解决新任务
现代机器学习系统的成功从根本上依赖于其训练数据的数量、质量和多样性。大规模互联网数据的可用性使得视觉和语言领域取得了显著进展。然而,数据的匮乏阻碍了机器人在类似领域的发展。人类演示数据的收集方法在数量和多样性上都难以达到足够的规模。如RT-1等项目证明了在17个月内收集的高质量人类数据的实用性。其他研究则开发了用于数据收集的低成本硬件。但所有这些方法都需要昂贵的人类数据收集过程。
自动化数据收集方法在多样性上同样难以达到足够的规模。随着视觉语言模型(VLMS)的出现,机器人领域涌现出了一系列利用VLMS指导机器人行为的新系统。在这些系统中,VLMS将任务分解为语言计划或生成代码来执行预定义技能。尽管这些方法在模拟环境中取得了成功,但在现实世界中却表现不佳。一些方法依赖于仅在模拟环境中可用的特权状态信息,需要手动设计的技能,或者仅限于操纵具有已知几何形状的固定对象集。
随着视觉语言模型(VLMs)性能的提升,以及它们所展现出的丰富常识知识,我们能否利用它们的能力来完成多样化的任务并生成可扩展的数据呢?答案是肯定的——通过精心设计的系统以及正确的输入和输出公式,我们不仅可以利用VLMs以零样本的方式成功执行多样化的任务,还可以生成大量高质量的数据来训练行为克隆策略。
我们提出了MANIPULATE-ANYTHING,这是一种可扩展的自动化演示生成方法,用于现实世界的机器人操作。MANIPULATE-ANYTHING可以产生高质量的数据,在需要时可以大量生成,并且能够操纵多样化的对象来执行多样化的任务。当放置在现实环境中并给定任务时,MANIPULATE-ANYTHING能够有效地利用VLMS来引导机械臂完成任务。与先前的方法不同,它不需要特权状态信息、手动设计的技能,也不局限于特定的对象实例。不依赖特权信息使得MANIPULATE-ANYTHING能够适用于不同的环境。MANIPULATE-ANYTHING规划一系列子目标,并生成执行这些子目标的动作。它可以使用验证器来验证机器人是否成功完成了子目标,并在需要时从当前状态重新规划。这种错误恢复机制能够识别错误、重新规划和从失败中恢复。它还将恢复行为注入到收集的演示中。我们通过结合多视角推理进一步增强了VLMs的能力,从而显著提高了性能。
MANIPULATE-ANYTHING是一种用于现实环境中机器人操作的自动化方法。与以往的方法不同,它不需要特权状态信息、手工设计的技能,也不局限于操作固定数量的对象实例。该方法能够引导机器人完成一系列不同的未见任务,操作各种对象。此外,生成的数据能够用于训练行为克隆策略,其性能优于使用人类演示进行训练的策略。
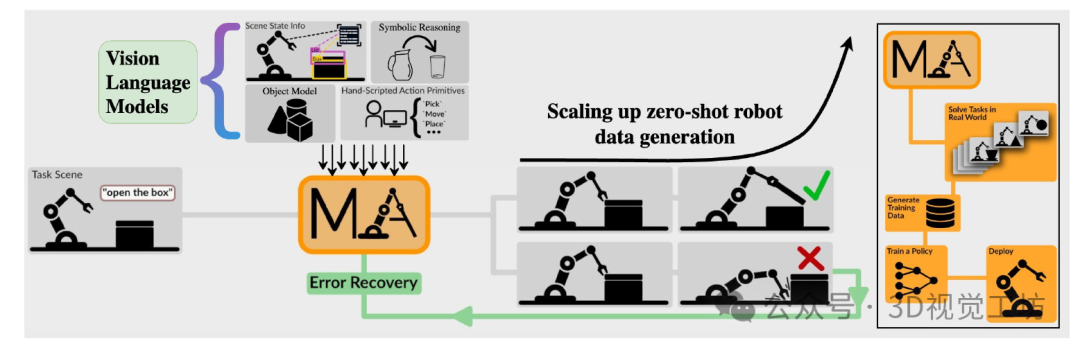
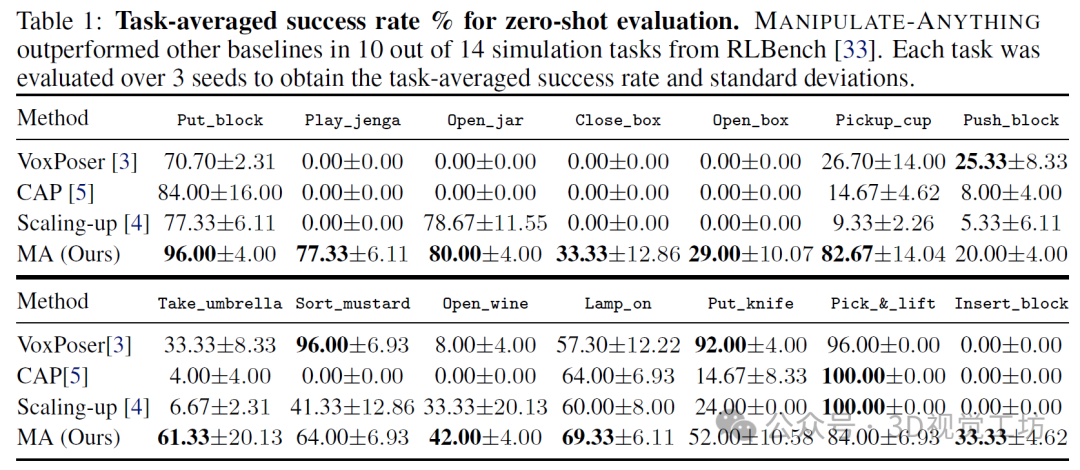
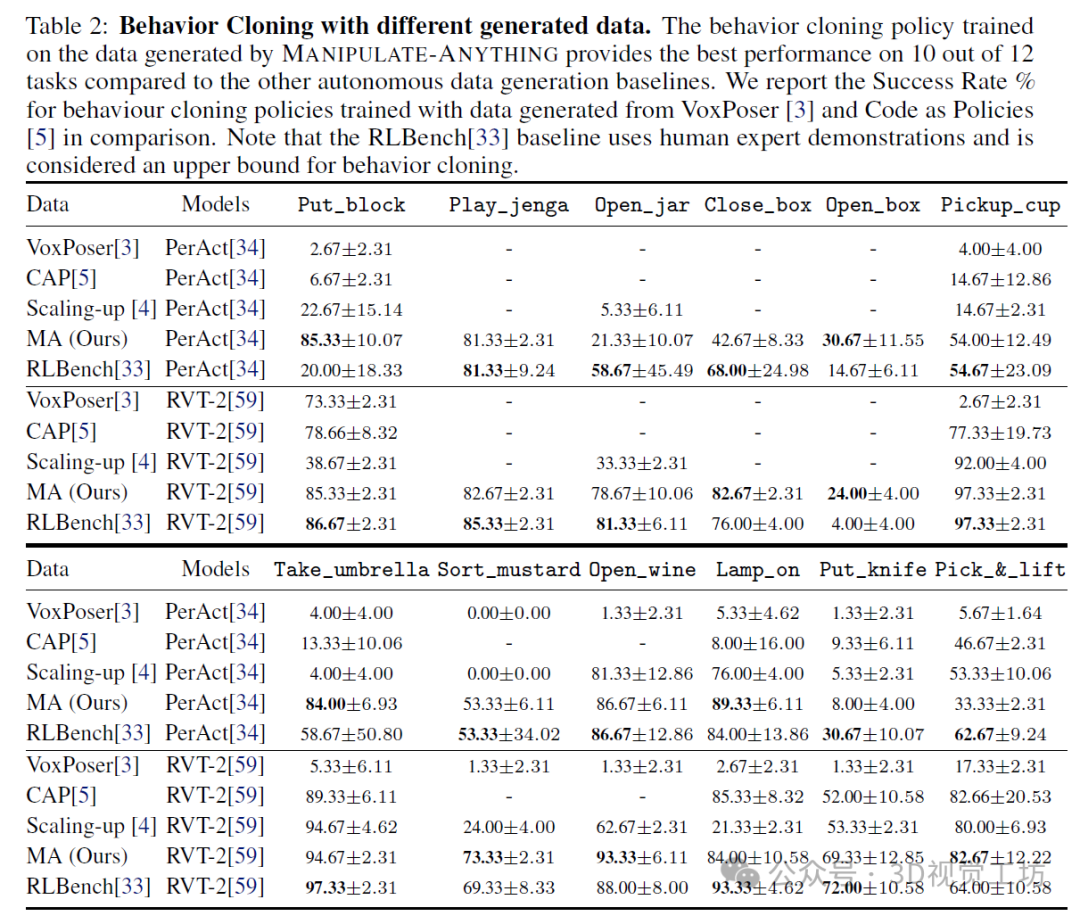
我们通过两个评估设置展示了MANIPULATE-ANYTHING的实用性。首先,我们展示了它可以接受一个全新的、从未见过的任务,并以零样本的方式完成它。我们在7个现实世界任务和14个RLBench模拟任务上进行了定量评估,并展示了在多个现实世界日常任务中的能力。我们的方法在14个模拟任务的零样本评估中有10个优于VoxPoser。它还能推广到VoxPoser因局限于特定对象实例而完全失败的任务。此外,我们还证明了我们的方法可以以零样本的方式解决现实世界中的操作任务,平均任务成功率为38.57%。其次,我们展示了MANIPULATE-ANYTHING可以为行为克隆策略生成有用的训练数据。我们将MANIPULATE-ANYTHING生成的数据与真实的手动脚本演示数据,以及来自VoxPoser、Scaling-up和Code-As-Policies的数据进行了比较。令人惊讶的是,在RVT-2的评估中,我们的数据训练出的策略在12项任务中有5项甚至优于人类手动脚本数据,另有4项表现相当。同时,基线方法无法为某些任务生成训练数据。MANIPULATE-ANYTHING展示了在非结构化现实环境中大规模部署机器人的广泛可能性,同时也凸显了其作为训练数据生成器的实用性,有助于实现机器人演示数据扩展的关键目标。推荐课程:国内首个面向具身智能方向的理论与实战课程。
“操作万物”框架。该过程始于将场景表示和自然语言任务指令输入到视觉语言模型(VLM)中,该模型识别对象并确定子任务。对于每个子任务,我们向动作生成模块提供多视图图像、验证条件和任务目标,以生成特定于任务的抓取姿态或动作代码。这将导致一个临时目标状态,该状态由子任务验证模块进行评估以实现错误恢复。一旦所有子任务都完成,我们会对轨迹进行过滤,以获得用于下游策略训练的成功演示。
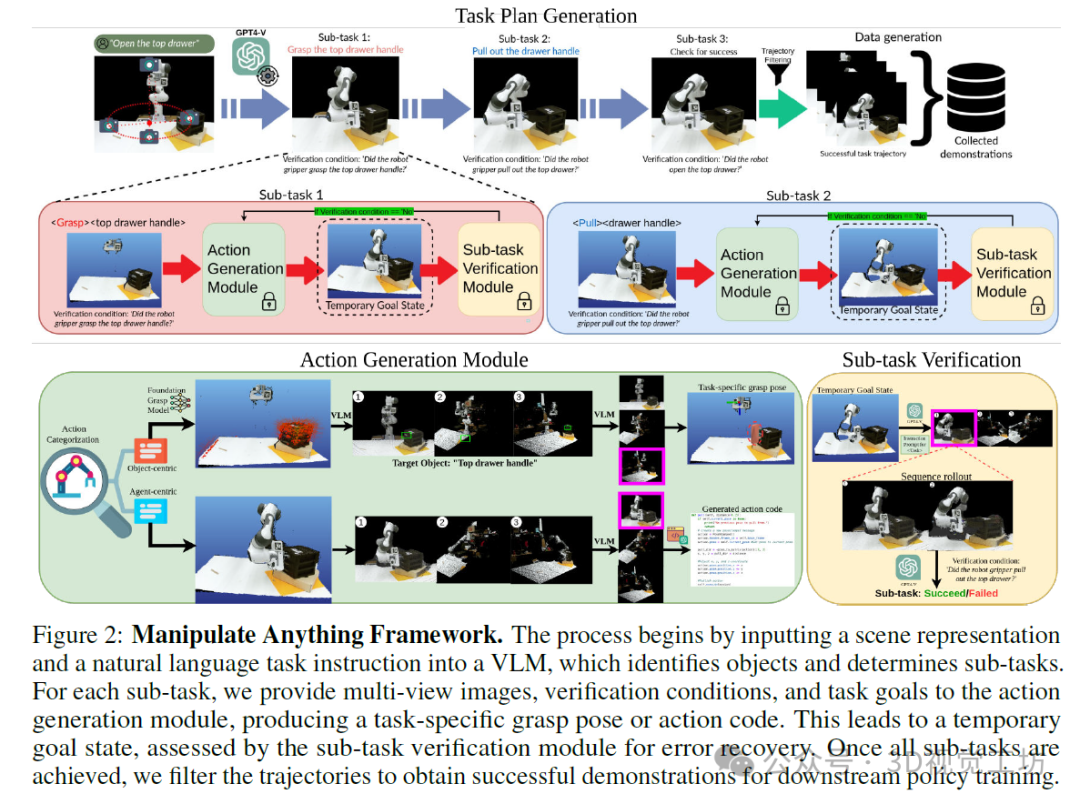
我们提出了MANIPULATE-ANYTHING框架,该框架能够解决基于语言的日常操作任务。在框架内部,MANIPULATE-ANYTHING利用视觉语言模型(VLM)将任务分解为子任务,生成新技能或特定于任务的抓取姿态的代码,并验证每个子任务的成功(见图3)。请注意,由于我们框架的模块化特性,随着底层视觉语言模型的不断改进,MANIPULATE-ANYTHING也将继续提升性能。

局限性。尽管取得了令人瞩目的成果,但MANIPULATE-ANYTHING仍存在若干局限性。首先,MANIPULATE-ANYTHING依赖于大型语言模型(VLMS)的可用性,这引入了对基础模型的依赖。然而,随着开源VLMS的不断发展,这一问题可能会随时间逐渐减弱。其次,MANIPULATE-ANYTHING在处理动态操作任务和非抓取任务时存在困难,因为它无法为这些场景生成替代的抓取姿态。第三,该系统高度模块化的特性,即集成了多个视觉语言模型(VLMs),在生成零样本轨迹时可能导致累积误差。新兴的专业化VLMs和其他技术可能有助于解决这一问题。最后,仍需要手动进行上下文学习中的提示工程。尽管如此,近期在对齐和提示技术方面的进展为减少提示工程的工作量提供了潜在解决方案。
结论。MANIPULATE-ANYTHING是一种可扩展且与环境无关的方法,用于在不使用特权环境信息的情况下为机器人任务生成零样本演示。MANIPULATE-ANYTHING利用VLMS进行高级规划和场景理解,并具有错误恢复能力。这能够为行为克隆生成高质量的数据,从而实现比使用人类数据更好的性能。
本文来自新知号自媒体,不代表商业新知观点和立场。 若有侵权嫌疑,请联系商业新知平台管理员。 联系方式:system@shangyexinzhi.com